

Data-driven businesses require Data Engineering, which forms the foundation of data analysis, machine learning, or even decision making in working processes. This demand arises from the fact that most companies create and process huge quantities of data therefore data engineering will be responsible for data organization, management, and optimization. In this guide, readers seeking to learn the basics of data engineering will be introduced to the key principles, types, strategies, and instruments typical of mastering this important domain of practice.
What is Data Engineering?
Data engineering is concerned with the design, construction and maintenance of the systems that house large datasets and undertake their processing and analysis. Data engineers ensure that data processes are not only accurate but efficient, including data pipelines, databases, and data warehouses. Constructing such systems makes it possible for data scientists, analysts and business units to make sense of accurate and structured data for easier decision making and data analysis.
Core Concepts in Data Engineering
To understand data engineering fundamentals, it’s essential to explore its core concepts. These concepts form the foundation of data engineering and are crucial for anyone entering the field.
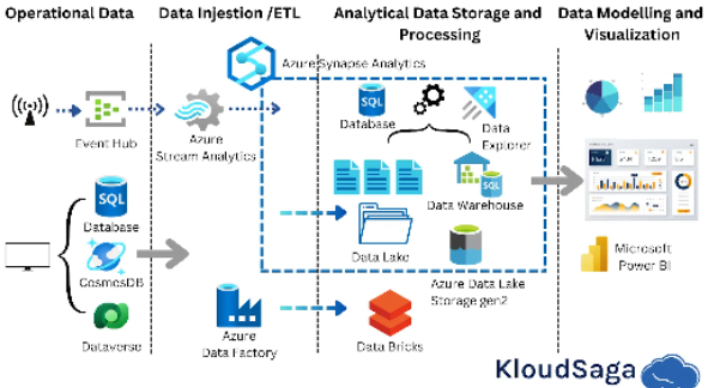
1. Data Pipelines
Data pipelines are sequences of data processing steps that automate the movement and transformation of data from one location to another. These pipelines are essential for integrating data from multiple sources, cleaning and transforming it, and loading it into data storage systems.
- ETL vs. ELT: ETL (Extract, Transform, Load) is a traditional approach where data is transformed before loading into the target system, while ELT (Extract, Load, Transform) involves loading raw data into a data warehouse and transforming it afterward. Both approaches have specific use cases, with ETL preferred for smaller datasets and ELT more common in big data environments.
2. Data Warehousing
A data warehouse is a centralized storage solution optimized for analytical queries. Data warehouses aggregate data from multiple sources, providing a single source of truth for reporting and analysis. They are designed for high-speed queries and large-scale data retrieval, making them ideal for supporting business intelligence (BI) and analytics.
- Popular Data Warehouses: Some widely used data warehouses include Amazon Redshift, Google BigQuery, and Snowflake. Each of these solutions offers unique features, scalability, and performance capabilities tailored to different organizational needs.
3. Data Lakes
Data lakes are storage solutions that hold vast amounts of raw, unstructured, or semi-structured data. Unlike data warehouses, data lakes store data in its native format, making them highly flexible and scalable. Data lakes are particularly useful in big data environments, where the volume, variety, and velocity of data require a cost-effective, scalable storage solution.
- Key Difference from Data Warehouses: While data warehouses are optimized for structured data and analytics, data lakes are designed for flexibility, supporting structured and unstructured data, including images, videos, and text.
4. Data Quality and Cleansing
Data quality is essential for accurate analysis and reliable decision-making. Data engineers must implement data cleansing techniques to identify and correct errors, inconsistencies, and duplicates in the data. High data quality ensures that data scientists and analysts work with accurate, reliable datasets, leading to better insights.
- Common Data Cleansing Techniques: Deduplication, data normalization, and validation are common techniques that help maintain data quality across the pipeline.
5. Data Transformation
Data transformation involves converting data from one format or structure to another, making it suitable for analysis and storage. Transformation steps often include data normalization, aggregation, and data enrichment, which involve adding additional information to datasets.
- Examples of Data Transformation: Converting date formats, calculating summary statistics, and creating categorical variables are examples of transformation tasks that prepare data for analysis.
Essential Skills for Data Engineers
A career in data engineering requires proficiency in specific technical skills, tools, and best practices. Here are some key skills that are fundamental to data engineering:
1. Programming Languages
Data engineers need to be proficient in programming languages like Python, SQL, and Java, as these languages are commonly used for data manipulation, database management, and automation.
- Python: Python is versatile and has many libraries like Pandas, Numpy, and PySpark for data manipulation and processing.
- SQL: SQL is essential for querying databases and manipulating relational data.
- Java and Scala: These languages are often used in big data frameworks like Apache Spark and Hadoop for large-scale data processing.
2. Big Data Technologies
Big data technologies enable the processing and storage of large datasets. Data engineers should be familiar with frameworks such as Hadoop and Spark, which allow them to handle massive amounts of data efficiently.
- Apache Hadoop: An open-source framework that enables distributed storage and processing of large datasets.
- Apache Spark: A fast, in-memory data processing framework known for its speed and flexibility, suitable for both batch and real-time data processing.
3. Data Modeling
Data modeling is the process of designing the structure of a database or data warehouse, organizing data into tables, schemas, and relationships. Effective data modeling allows for efficient data retrieval and storage.
- Star Schema and Snowflake Schema: These are common data modeling techniques used in data warehouses, facilitating faster queries and organized data storage.
4. ETL/ELT Tools
ETL and ELT tools automate the extraction, transformation, and loading of data. These tools are essential for building robust data pipelines and ensuring data flows smoothly from sources to target storage.
- Popular Tools: Informatica, Talend, Apache Nifi, and AWS Glue are commonly used ETL tools in data engineering.
5. Cloud Platforms
With the growing trend of cloud-based storage and processing, data engineers need to understand cloud platforms like AWS, Google Cloud Platform (GCP), and Microsoft Azure. These platforms provide services for data storage, processing, and machine learning, making it easier to scale and manage data infrastructure.
- Cloud Services for Data Engineering: AWS S3, GCP BigQuery, and Azure Data Lake are examples of cloud storage services, while AWS Glue and Google Cloud Dataflow support data processing.
Key Tools in Data Engineering
Data engineers use a variety of tools for data ingestion, processing, storage, and analysis. Here’s a look at some of the key tools essential for data engineering:
1. Apache Airflow
Apache Airflow is an open-source platform for orchestrating workflows. It’s widely used for scheduling and managing data pipelines, allowing data engineers to automate tasks, monitor workflow progress, and ensure that data pipelines run efficiently.
2. Kafka
Kafka is a distributed streaming platform that enables the real-time ingestion and processing of data. It’s commonly used in scenarios where data needs to be processed in real-time, such as event tracking, monitoring, and streaming analytics.
3. Tableau and Power BI
While data engineers focus on building data pipelines, data visualization tools like Tableau and Power BI are essential for delivering data insights to stakeholders. These tools allow data engineers and analysts to create interactive dashboards that display metrics and trends, supporting data-driven decision-making.
4. Apache Hive
Hive is a data warehousing tool that runs on top of Hadoop, allowing for SQL-like queries to process large datasets stored in Hadoop’s distributed file system (HDFS). It simplifies querying in big data environments, making it ideal for data engineers who need to work with massive datasets.
5. Databricks
Databricks is a cloud-based data engineering platform built on Apache Spark. It provides collaborative tools for data engineers and data scientists to manage data workflows, supporting machine learning and real-time analytics.
Best Practices in Data Engineering
To excel in data engineering, following best practices ensures efficiency, reliability, and scalability of data pipelines and systems.
1. Automate Data Processes
Automation reduces manual intervention, ensuring data pipelines run consistently and accurately. Automated workflows enable data engineers to focus on optimization and troubleshooting rather than repetitive tasks.
2. Ensure Data Quality
Data quality checks should be embedded in every step of the data pipeline to prevent errors from affecting downstream processes. Implement validation, deduplication, and error logging to maintain high-quality datasets.
3. Optimize for Performance
Optimizing data storage, retrieval, and processing is critical in data engineering. Techniques such as partitioning, indexing, and caching can greatly improve system performance, especially with large datasets.
4. Secure Data Pipelines
Data security is paramount in data engineering. Ensure that sensitive data is encrypted, access is controlled, and compliance with data protection regulations is maintained.
Conclusion: Building a Strong Foundation in Data Engineering
Understanding core principles of data engineering is essential to the design, construct, and maintenance of data systems that are reliable, capable, and performant. It is the data engineers who make sense of the texts using data pipelines, data warehousing, big-data tools, cloud services, and other technologies all of which are essential for effective data spheres. There is a need for any newcomer in the industry to possess good knowledge of these tools and concepts since this will enhance their prospects in this field as they will be able to promote data-driven strategies and enhance the growth of the organization.
As with other best practices, modern technologies assist data engineers in maximizing the use of data by the objectives of the organization or company to improve decision making, and strategic direction.


